A Reference Phenotyping System for Energy Sorghum
Technology Description:
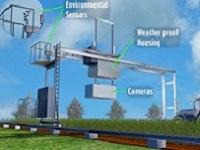
The Donald Danforth Plant Science Center, in collaboration with partners from seven institutions, proposes an integrated open-sourced phenotyping system for energy sorghum. Phenotyping is the assessment of observable plant traits, and is critical for breeding improvements. The team will develop a central repository for high quality phenotyping datasets, and make this resource available to other TERRA project groups and the wider community to stimulate further innovations. The team will collect data with their complete system that will include a number of components. First, the team will install, operate, and maintain a reference phenotyping field system that employs a bridge-like overhead structure with a moveable platform supporting sensing equipment, called the Scanalyzer, at the Maricopa Agricultural Center (MAC) at the University of Arizona. The Scanalyzer’s advanced sensors will be used for automated high-throughput phenotyping to gather data from the energy sorghum in the field. Second, the project will combine field- and controlled-environment phenotyping. The controlled-environment facilities allow the team to more precisely manipulate environmental conditions and resolve complex dynamic interactions observed in the field. Third, plant and environment data gathered will be used to create computational solutions and predictive algorithms to improve the ability to predict phenotypes; increasing the ability to identify traits for improved biomass yield earlier in a plant's development. Collected data will also be used in the fourth component of the project, advancing our understanding of phenotype-to-genotype trait associations, determining which genes control observable traits in the sorghum. Some traits are largely determined by genes and others are largely determined by environmental factors; work in this project will help elucidate the differences. All of these components generate an incredible amount of data. An “Open Data” policy is central to the philosophy of the Danforth project. To ensure that this data is useful, the team will convene a standards committee selected in collaboration with the TERRA program to standardize phenotyping efforts between institutions. This sharing of standards, data, and open-source code will reduce redundancy, lower costs for researchers, allow for long-term curation, and unlock potential new innovations from entrepreneurs outside the TERRA community.
Potential Impact:
If successful, the Danforth Center's system will lead to advances in high throughput phenotyping, which will transform crop breeding and advanced biofuel production.
Security:
Improved biofuel crops could lead to increased production of domestic biofuels, reducing dependence on foreign sources of transportation fuels.
Environment:
Increased use of advanced biofuels could significantly reduce CO2 emissions from transportation, and improved varieties of biofuel crops could preserve natural resources, conserve water, and reduce fertilizer N2O emissions.
Economy:
The establishment of industry standards along with shared open-source code and data will enable broad-scale innovation opportunities for the public and private sectors, stimulating new business development opportunities.
Contact
ARPA-E Program Director:
Dr. Patrick McGrath
Project Contact:
Dr. Todd Mockler
Press and General Inquiries Email:
ARPA-E-Comms@hq.doe.gov
Project Contact Email:
tmockler@danforthcenter.org
Partners
University of Arizona
Texas A&M University
Clemson University
HudsonAlpha
Kansas State University
University of Illinois, Urbana Champaign
Washington University
Related Projects
Release Date:
10/01/2014